

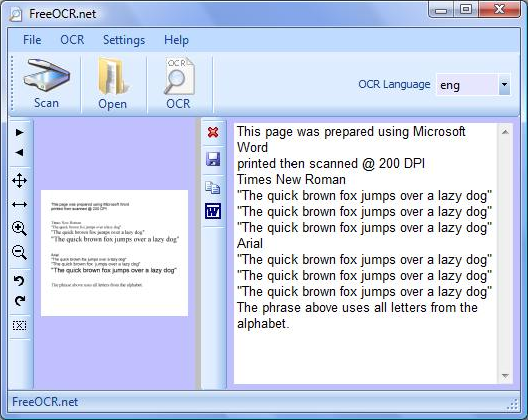
FreeOCR is a basic optical character recognition package that will quickly extract the text from scanned documents, images or PDF files.
The program's clean and simple interface means it's easy to get started. At the click of a button it can import a page from your scanner, open a PDF file or an image (TIF, BMP, JPG, GIF and PNG formats are supported). Then one more click on the OCR button and FreeOCR will scan your image for text, displaying it in a separate window.
The accuracy of the results proved variable, in our tests: you may have to spend some time editing the finished text before you get quality results. (The OCR engine also requires images with a resolution of at least 200dpi, so screen grabs are unlikely to produce useful results.)
And while FreeOCR can open multi-page PDFs, you must work through them manually, one at a time, which could prove tedious for lengthy documents.
Still, with the right documents FreeOCR could still save you a great deal of time, and it's so easy to use that it won't take long to find out if this is the right tool for you. Well worth a look. But please note: the program will attempt to install additional elements prior to installing the main program - read each EULA carefully, and click Decline to avoid installing potentially unwanted software.
What's new in 5.4.1?
- Testing with Windows 10 (Technical Preview)
- Scanning fixes to makes/models of scanner
- Better PDF compatibility for PDF Open function
- Minor fixes
Verdict:
FreeOCR has its limitations, but we can't really complain at this price, and if your OCR requirements are simple then it may provide everything you need
Your Comments & Opinion
Reap the benefits of OCR with your digital camera
Clean up your scanned documents with this easy-to-use tool
Grab text from images, videos and more
Use OCR to capture small amounts of text, saving the results to the clipboard
Scan documents to create editable PDFs with your mobile
Keep your desktop in order with this icon organisation tool
Manage your files and folders with this dual pane tabbed Explorer replacement
Create, format, merge, resize, move and otherwise organise your drive partitions with this free tool
A configurable system monitor
A configurable system monitor